Chapter 4 Target retrieval and DEG analysis
In network pharmacology analysis, disease target retrieval and differential gene screening are two essential preparatory steps. This chapter introduces common and free disease target databases and their retrieval strategies, demonstrates volcano plot visualization of DESeq2 results, and performs intersection analysis between DEGs and disease targets using Venn and UpSet plots.
4.1 Programmatic disease target retrieval with TCMDATA
Before manually browsing individual databases, it is worth noting that TCMDATA provides convenient functions for programmatic disease–gene association retrieval. Currently, two complementary routes are supported:
search_disease()andsearch_gene_disease()retrieve disease-gene associations from the DisGeNET dataset bundled in theDOSEBioconductor package.search_disease_efo(),get_disease_targets(), andquery_disease_targets()retrieve scored disease-target associations from the Open Targets Platform GraphQL API.
The DOSE/DisGeNET route is useful for fast local lookup, while Open Targets is preferred when target-level association scores are needed for target weighting or PPI-based prioritization.
For the DN case study used in this book, TCMDATA also includes dn_otp_tbl, a built-in Open Targets-derived table that retains the target-level score column, in addition to the legacy symbol vector dn_otp.
4.1.1 search_disease(): disease → genes
search_disease() accepts a disease name (fuzzy matching supported) or a UMLS CUI identifier, and returns all associated genes with their Entrez IDs and gene symbols:
library(TCMDATA)
## search by disease name
dn_targets <- search_disease("diabetic nephropathy")
head(dn_targets) disease_id gene_id disease_name symbol
1 C0011881 10 Diabetic Nephropathy NAT2
2 C0011881 1000 Diabetic Nephropathy CDH2
3 C0011881 100033819 Diabetic Nephropathy MIR675
4 C0011881 100048912 Diabetic Nephropathy CDKN2B-AS1
5 C0011881 100124700 Diabetic Nephropathy HOTAIR
6 C0011881 100125288 Diabetic Nephropathy ZGLP1You can also query by UMLS CUI for precise matching, or search multiple diseases at once:
4.1.2 search_gene_disease(): gene → diseases
The reverse lookup function search_gene_disease() finds all diseases associated with a given gene, which is useful for validating whether hub genes from network analysis have known disease relevance:
## which diseases are associated with TNF?
tnf_diseases <- search_gene_disease("TNF")
cat("TNF is associated with", length(unique(tnf_diseases$disease_name)), "diseases\n")
head(tnf_diseases[, c("disease_name", "gene_id", "symbol")])TNF is associated with 2724 diseases
disease_name gene_id symbol
1 (non-specific) purulent meningitis 7124 TNF
2 AA amyloidosis 7124 TNF
3 Abdominal Abscess 7124 TNF
4 Abdominal Pain 7124 TNF
5 Abdominal symptom 7124 TNF
6 ABLEPHARON-MACROSTOMIA SYNDROME 7124 TNF## query multiple genes
hub_diseases <- search_gene_disease(c("IL6", "TNF", "PPARG"))
## top diseases shared by all three genes
shared <- Reduce(intersect, split(hub_diseases$disease_name, hub_diseases$symbol))
cat("Diseases shared by IL6, TNF, PPARG:", length(shared), "\n")
head(shared)Diseases shared by IL6, TNF, PPARG: 516
[1] "Abnormal behavior" "Acanthosis Nigricans" "Acne"
[4] "Acne Vulgaris" "Acute Chest Syndrome" "Acute colitis"4.1.3 Open Targets API: disease → scored targets
Open Targets provides an overall association score for each disease-target pair. This score is especially useful when disease targets should be treated as weighted evidence rather than a simple unweighted gene set.
The recommended workflow is:
- Search the disease ontology identifier.
- Retrieve associated targets by EFO/MONDO/Orphanet ID.
- Keep the
scorecolumn for downstream weighting.
library(TCMDATA)
## Step 1: inspect disease ontology matches
search_disease_efo("diabetic nephropathy", size = 5)
## Step 2: retrieve associated targets from the selected disease ID
dn_ot <- get_disease_targets("EFO_0000401", size = 500, score_threshold = 0.05)
head(dn_ot) ensembl_id gene_symbol gene_name biotype score
1 ENSG00000159640 ACE angiotensin... protein_coding 0.7654
2 ENSG00000144891 AGTR1 angiotensin... protein_coding 0.5903
3 ENSG00000148737 TCF7L2 transcription... protein_coding 0.5131
4 ENSG00000254647 INS insulin protein_coding 0.4939Alternatively, query_disease_targets() combines disease-name search and target retrieval in one call:
dn_ot <- query_disease_targets(
disease_name = "diabetic nephropathy",
size = 500,
score_threshold = 0.05
)
dn_ot_targets <- dn_ot$gene_symbolIf the disease name is ambiguous, first run search_disease_efo() and then pass the exact disease ID to get_disease_targets(). This is usually safer for reproducible analysis.
For reproducible examples without online API calls, the built-in dn_otp_tbl object can be used directly:
4.2 Disease target databases
Multiple public databases catalogue gene–disease associations with varying evidence levels. In practice, combining targets from multiple sources (often intersection) improves both coverage and reliability. Here, we introduce some commonly used and user-friendly databases for disease target retrieval in TCM network pharmacology research.
4.2.1 GeneCards
GeneCards is an integrative database that provides comprehensive information on human genes, including disease associations (Stelzer et al., 2016). Each gene–disease link is assigned a Relevance Score that summarizes evidence from multiple sources.
However, GeneCards does not offer a direct API for bulk retrieval, so the common workflow involves manual search and export.
For example, to retrieve targets for “Diabetic Nephropathy”, we can manually search GeneCards, export the results as a CSV file, and filter by Relevance Score.
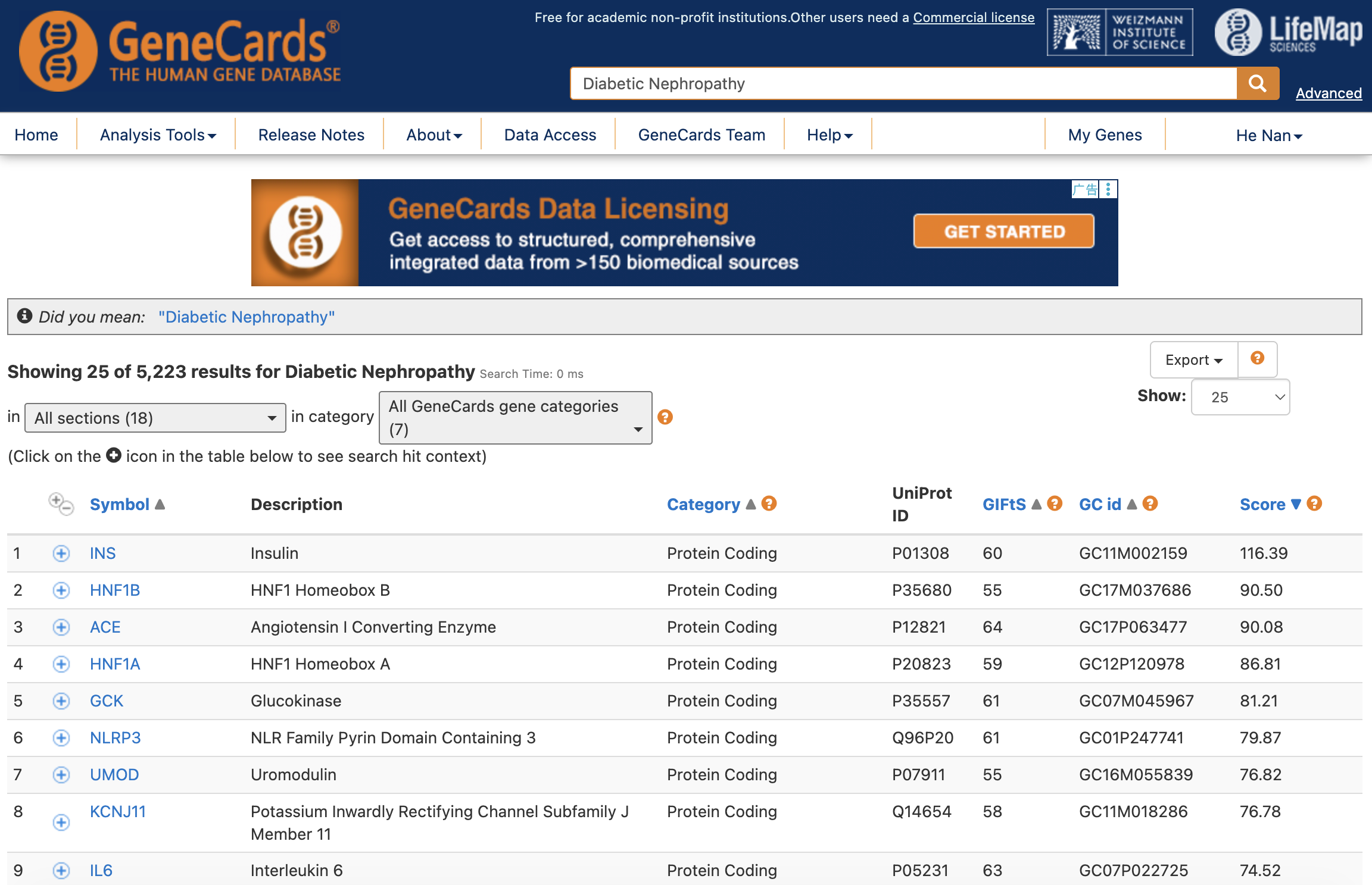
Then, we can read the exported CSV and filter genes based on the Relevance Score:
## uploaded "GeneCards-SearchResults.csv" from GeneCards export
dn_raw <- read.csv("GeneCards-SearchResults.csv")
## subset genes with Relevance Score > 10
dn_targets <- dn_raw$Gene.Symbol[dn_raw$Relevance.Score > 10]
head(dn_targets)[1] "INS" "HNF1B" "ACE" "HNF1A" "GCK" "NLRP3"Notably, TCMDATA provides a built-in GeneCards-derived target list for Diabetic Nephropathy for case study demonstration:
#> [1] "INS" "ACE" "GCK" "HNF1A" "HNF1B" "KCNJ11" "UMOD"
#> [8] "ABCC8" "IL6" "PPARG" "HNF4A" "WFS1" "COL4A1" "NLRP3"
#> [15] "TCF7L2" "PDX1" "INSR" "TNF" "NEUROD1" "TGFBR2"4.2.2 Open Targets Platform
The Open Targets Platform is a comprehensive and robust resource designed for therapeutic target identification and prioritization (Buniello et al., 2025). It systematically aggregates, validates, and scores evidence linking targets to diseases across heterogeneous data sources. By organizing its knowledge base around five core entities—Target, Disease/Phenotype, Variant, Study, and Drug—the platform provides a highly structured framework that facilitates hypothesis generation and evidence-based target selection in drug discovery.
User can retrieve disease targets by both API and web interface. The API allows programmatic access to the data, while the web interface provides an intuitive way to explore target–disease associations.
For web interface, “Diabetic Nephropathy” can be searched directly, and the resulting target list can be exported as json and tsv format for downstream analysis:
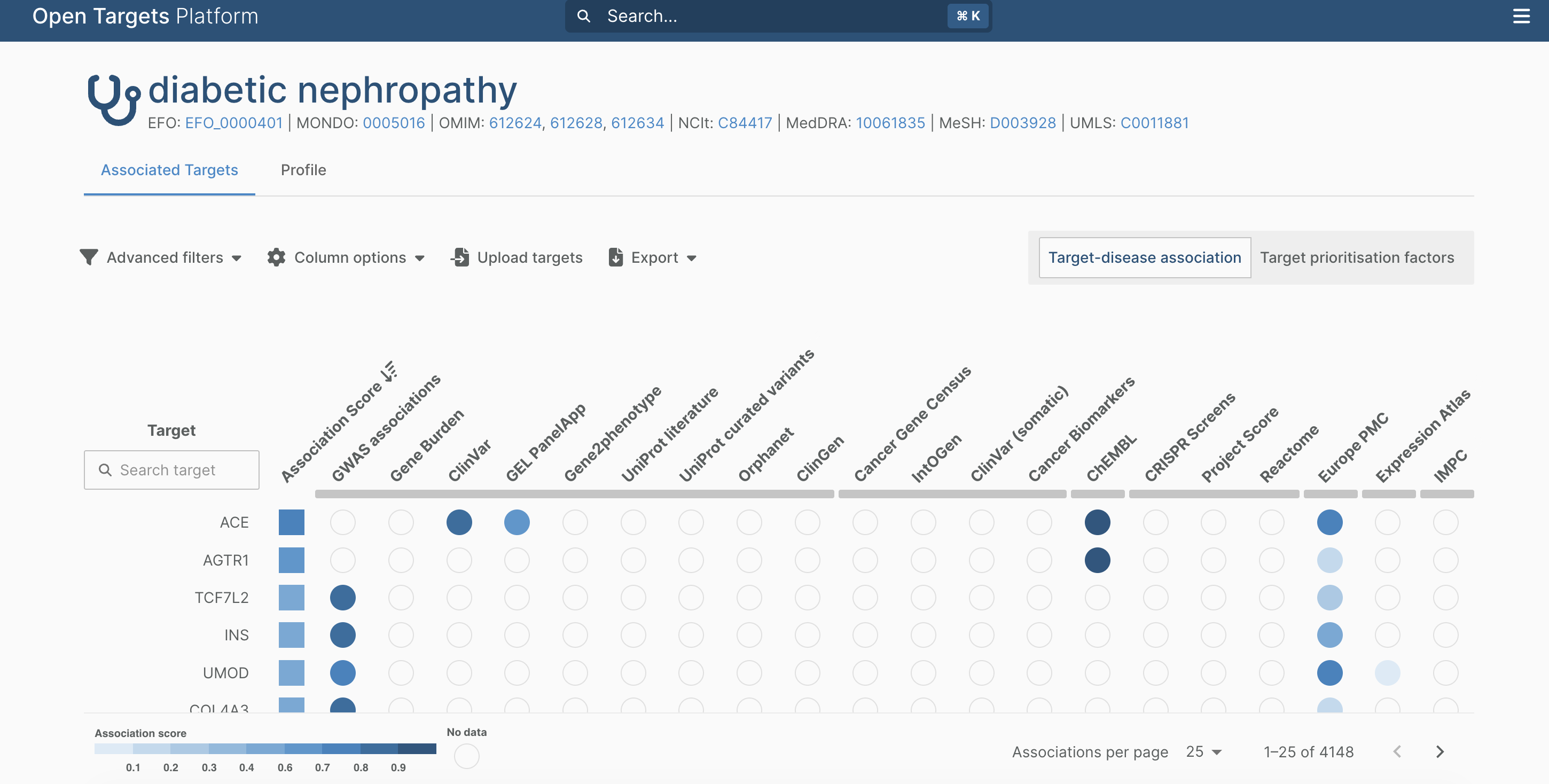
symbol globalScore gwasCredibleSets geneBurden eva
1 ACE 0.7654601 No data No data 0.8841439697057125
2 AGTR1 0.5902786 No data No data No data
3 TCF7L2 0.5130827 0.8296366016990858 No data No data
4 INS 0.4939346 0.7894596444737526 No data No data
5 UMOD 0.4840121 0.7620249013066388 No data No data
6 COL4A3 0.4821762 0.7850753632678814 No data No dataFor API access, please refer to the Open Targets API documentation for detailed instructions on how to query target–disease associations programmatically.
4.2.3 CTD (Comparative Toxicogenomics Database)
The Comparative Toxicogenomics Database (CTD) is a robust, publicly available resource that aims to advance understanding about how environmental exposures affect human health (Davis et al., 2024). It provides manually curated information about chemical–gene/protein interactions, chemical–disease, and gene–disease relationships. By integrating these data with functional and pathway annotations, CTD helps researchers develop hypotheses about the mechanisms underlying environmentally influenced diseases. It is particularly valuable for network pharmacology studies involving environmental toxins or pharmacological exposures.
CTD provides both a web interface and a RESTful API for data retrieval. The web interface allows users to perform batch queries for diseases, chemicals, or genes, and export the results manually.
For programmatic access, the CTD Batch Query API is highly efficient. You can construct a query URL specifying the input type (disease), the query term (Diabetic Nephropathy), the desired report type (genes_curated or genes_inferred), and the output format (csv or tsv).
The report parameter controls which association types are returned:
report value |
Description | DN example |
|---|---|---|
genes_curated |
Manually curated from literature (high confidence) | 46 genes |
genes_inferred |
Inferred via chemical–gene–disease links | ~26,000 genes |
genes |
All associations (curated + inferred) | ~26,300 genes |
For example, to retrieve all gene targets associated with “Diabetic Nephropathy” directly into R:
# Construct the CTD Batch Query API URL
# Change report to "genes_curated" for high-confidence curated associations only
options(timeout = 300)
ctd_url <- paste0(
"https://ctdbase.org/tools/batchQuery.go?",
"inputType=disease&",
"inputTerms=Diabetic%20Nephropathy&",
"report=genes&",
"format=tsv"
)
lines <- readLines(ctd_url)
lines[1] <- sub("^# ", "", lines[1])
ctd <- read.delim(textConnection(lines))
# Extract unique gene symbols
ctd_targets <- unique(ctd$GeneSymbol)
cat("Total gene targets:", length(ctd_targets), "\n")
head(ctd[, c("GeneSymbol", "GeneID", "DirectEvidence", "InferenceScore")])Total gene targets: 26330
GeneSymbol GeneID DirectEvidence InferenceScore
1 1700001K19RIKL 299330 3.99
2 1-SF 100049428 2.47
3 9530082P21RIKL 360487 3.94
4 9930111J21RIK2 245240 3.74
5 A 50518 marker/mechanism NA
6 A 50518 2.63The InferenceScore column quantifies the strength of inferred associations — higher values indicate more atypical (and potentially more meaningful) connectivity in the chemical–gene–disease network. Rows with DirectEvidence filled and InferenceScore = NA are curated associations.
Further details about the CTD data retrieval and interpretation can be found in the CTD documentation.
4.2.4 Other databases
In addition to the databases detailed above, several other resources are frequently used in network pharmacology to ensure comprehensive target collection:
- DisGeNET: One of the largest publicly available collections of genes and variants associated with human diseases. It integrates data from expert-curated repositories, GWAS catalogues, animal models, and text-mining of the scientific literature.
- OMIM (Online Mendelian Inheritance in Man): A comprehensive, authoritative compendium of human genes and genetic phenotypes. It is highly reliable for identifying genes with strong, well-documented genetic links to specific diseases.
- TTD (Therapeutic Target Database): Focuses on known and explored therapeutic protein and nucleic acid targets, providing detailed information about the targeted diseases, pathway information, and corresponding drugs.
- DrugBank: While primarily a drug database, it provides extensive information on drug targets, making it useful for finding targets of existing drugs used to treat the disease of interest.
Researchers typically query multiple databases and take intersection of the results to form a robust disease target set.
4.3 Compound target prediction
In addition to disease-associated genes, target retrieval on the compound side is also an essential step in network pharmacology analysis. For many herbal ingredients or small-molecule constituents, experimentally validated targets are often incomplete or unavailable in public databases. Therefore, in silico target prediction tools are commonly used to expand the candidate target space before downstream intersection, network construction, and enrichment analysis.
Among the currently most widely used strategies, SwissTargetPrediction and Similarity Ensemble Approach (SEA) are two representative and user-friendly resources for predicting potential targets of small molecules. Although both methods are based on the principle that structurally or chemically similar compounds tend to interact with similar proteins, they differ in their implementation details, scoring systems, and output formats. In practice, researchers often use one or both resources to obtain a broader and more comprehensive target set for compound-level network pharmacology studies.
4.3.1 SwissTargetPrediction
SwissTargetPrediction is one of the most commonly used web-based tools for predicting the potential targets of bioactive small molecules (Daina et al., 2019). It was developed based on the assumption that similar molecules are likely to bind similar targets, and it combines both 2D chemical similarity and 3D molecular similarity to compare a query compound against a curated collection of ligands with known experimentally validated targets.
Users can submit a compound by entering its SMILES string, drawing the chemical structure, or uploading a molecular file. After the query is processed, the platform returns a ranked list of predicted protein targets, usually accompanied by target class annotation, probability scores, and related chemical information. The results are intuitive and convenient for manual browsing, making SwissTargetPrediction particularly suitable for studies involving a limited number of herbal ingredients or representative active compounds.
In network pharmacology studies of TCM, SwissTargetPrediction is often used to supplement missing target annotations for monomeric compounds derived from herbs. Its main advantage lies in its ease of use and clear output, which facilitates quick target collection and downstream standardization of gene symbols. However, users should note that the predictions are still model-based inferences rather than direct experimental evidence. Therefore, the predicted targets are usually filtered further by species, probability, target type, or by taking the intersection with disease targets and DEGs, so as to improve biological plausibility and reduce false-positive results.
To get SMILES of your query compounds, it is easy to use resolve_cid() and getprops() functions in TCMDATA to retrieve the canonical SMILES for a list of CIDs:
## suppose you have a vector of CIDs for your compounds of interest (lingzhi example)
library(TCMDATA)
herbs <- c("灵芝")
lz_mol <- search_herb(herb = herbs, type = "Herb_cn_name")$molecule |> unique() |> head(1)
lz_mol_cid <- resolve_cid(lz_mol, from = "name")
lz_mol_smiles <- getprops(lz_mol_cid, properties = "CanonicalSMILES")
print(lz_mol_smiles)# A tibble: 1 × 3
# cid CID ConnectivitySMILES
# <chr> <chr> <chr>
#1 72 72 C1=CC(=C(C=C1C(=O)O)O)O
The predicted targets can be downloaded as a CSV file, which can be read into R for further processing and integration with disease targets and DEGs in the network pharmacology workflow using TCMDATA.
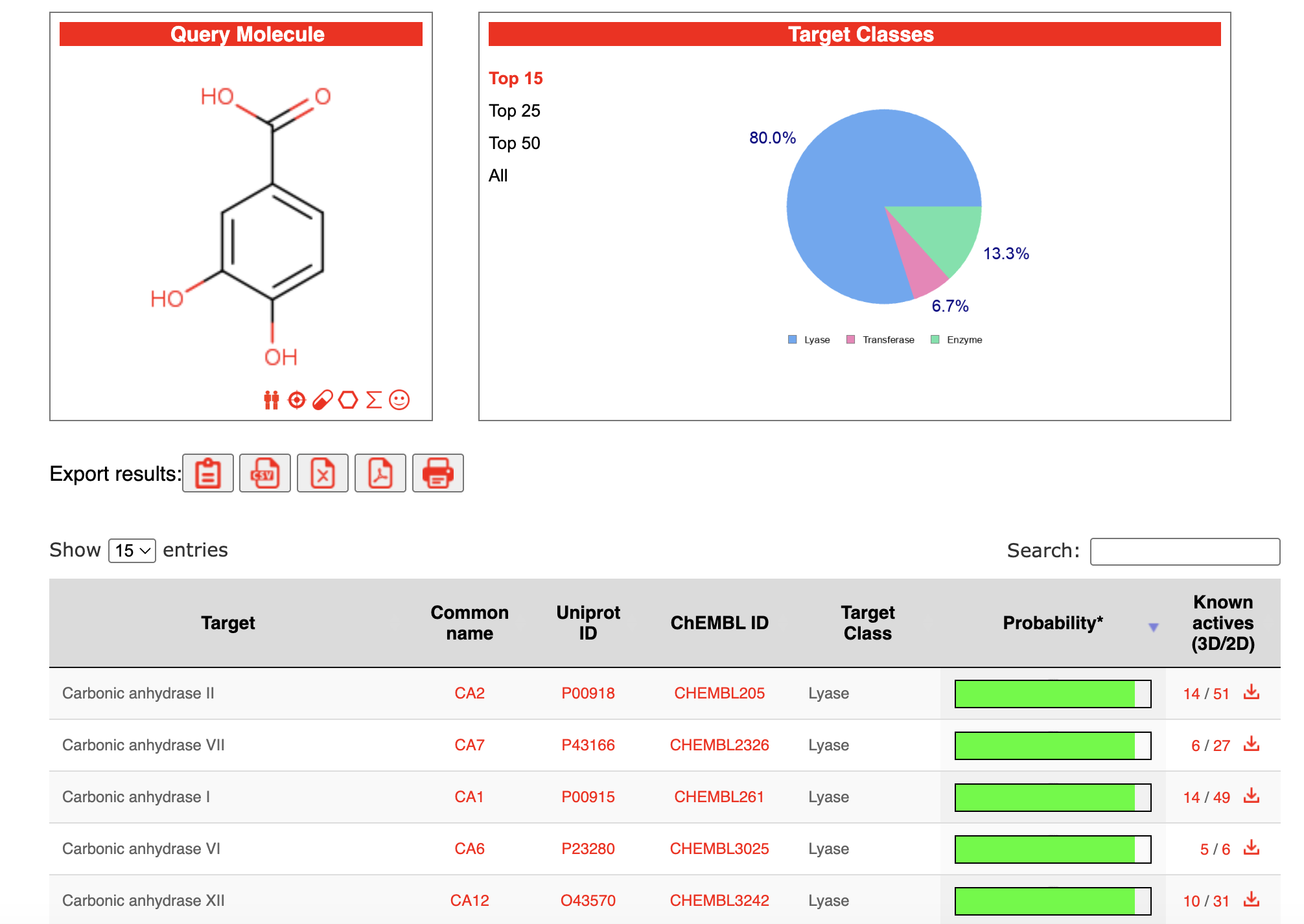
4.3.2 Similarity Ensemble Approach (SEA)
The Similarity Ensemble Approach (SEA) is another widely used ligand-based method for target prediction. Unlike single-pair similarity scoring, SEA evaluates the relationship between a query compound and an entire ligand set known to bind a given protein target. In other words, it compares the chemical similarity between the submitted molecule and the ensemble of known ligands for each target, and then assesses whether the observed similarity is greater than expected by chance.
A key feature of SEA is that it provides a more statistically oriented framework for target prediction. Its output commonly includes predicted targets together with measures such as E-values, significance scores, or confidence-related statistics, which help users judge the relative reliability of the predictions. Because of this set-to-set comparison strategy, SEA is often considered a useful complement to other chemical similarity tools, especially when researchers want to broaden the search space for potential compound–target associations.
In the context of TCM network pharmacology, SEA is frequently applied to predict candidate protein targets for herbal monomers whose direct experimental annotations are sparse. The predicted targets can then be merged with results from SwissTargetPrediction or other databases to form a more comprehensive compound target pool. As with all computational prediction tools, SEA results should be interpreted cautiously and are generally recommended for candidate expansion and prioritization, rather than being treated as definitive evidence. A common practice is to retain overlapping targets supported by multiple prediction resources and then integrate them with disease targets and transcriptomic signals for subsequent network analysis.
Also, we set “C1=CC(=C(C=C1C(=O)O)O)O” as SEA input, and results are as follows:
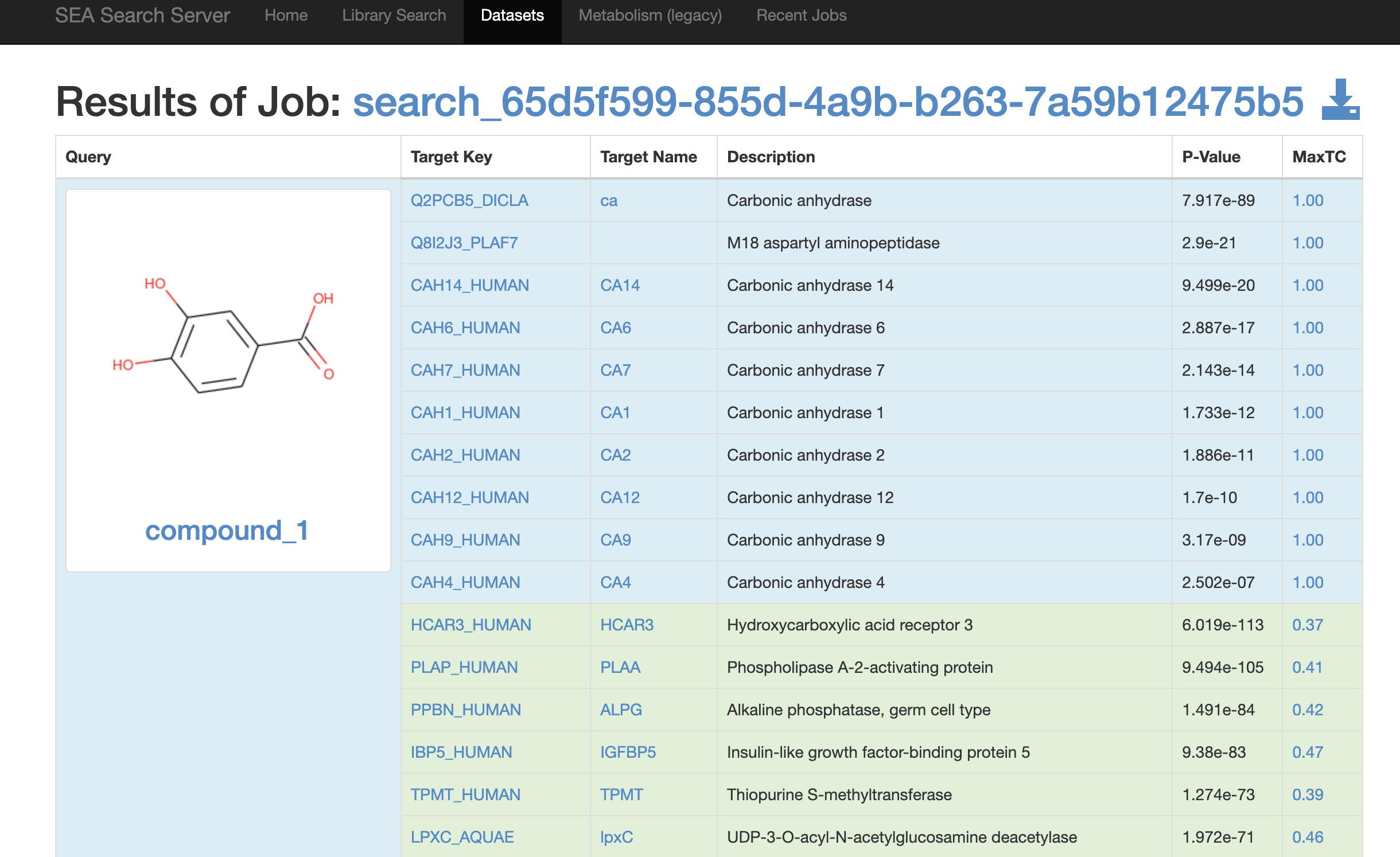
The predicted targets can be downloaded and read into R for further integration with disease targets and DEGs in the network pharmacology workflow using TCMDATA.
4.4 DEG visualization
Differential expression analysis identifies genes that are significantly altered between disease and control conditions. In the pharmacology network analysis, these DEGs can be integrated with disease targets to prioritize genes that are both statistically significant in expression and biologically linked to the disease phenotype. The intersection of DEGs and disease targets often represents the most promising candidates for further network analysis and experimental validation.
TCMDATA includes a demo DESeq2 result[4] from GSE142025[5] (early DN vs. control) for illustration. Further details about the dataset can be found in the original GEO page.
4.4.1 Load and inspect data
#> 'data.frame': 27183 obs. of 8 variables:
#> $ baseMean : num 31.9 1128.6 61.8 11.7 260.2 ...
#> $ log2FoldChange: num 0.8175 -0.0325 -0.2766 0.0321 0.0982 ...
#> $ lfcSE : num 0.219 0.133 0.266 0.421 0.178 ...
#> $ stat : num 3.7246 -0.2439 -1.0382 0.0763 0.5528 ...
#> $ pvalue : num 0.000196 0.807271 0.299167 0.939176 0.580368 ...
#> $ padj : num 0.00409 0.91812 0.56789 0.97605 0.78759 ...
#> $ names : chr "DDX11L1" "WASH7P" "MIR6859-1" "FAM138A" ...
#> $ g : chr "up" "normal" "normal" "normal" ...#>
#> down normal up
#> 678 25852 6534.4.2 Volcano plot with ivolcano
ivolcano[6] is an R package that provides both static and interactive volcano plot visualizations for differential expression results. The interactive mode allows users to explore DEGs dynamically, which hovers to display gene details, click to redirect to external databases, and zoom into specific regions.
By specifying dual thresholds, ivolcano automatically applies a FigureYa-styled color scheme that clearly separates genes into significance tiers.