UKBAnalytica
UKBAnalytica is an R package for analyzing with the UK Biobank Research Analysis Platform (RAP) data inside approved RAP projects. It focuses on standardized phenotyping, survival-ready datasets, scalable preprocessing, and downstream analysis.
The package does not ship UK Biobank participant-level source records. Examples use field IDs, runtime-generated fully synthetic toy data, or user-provided tables that remain within RAP-controlled storage.
![]()
What the package covers
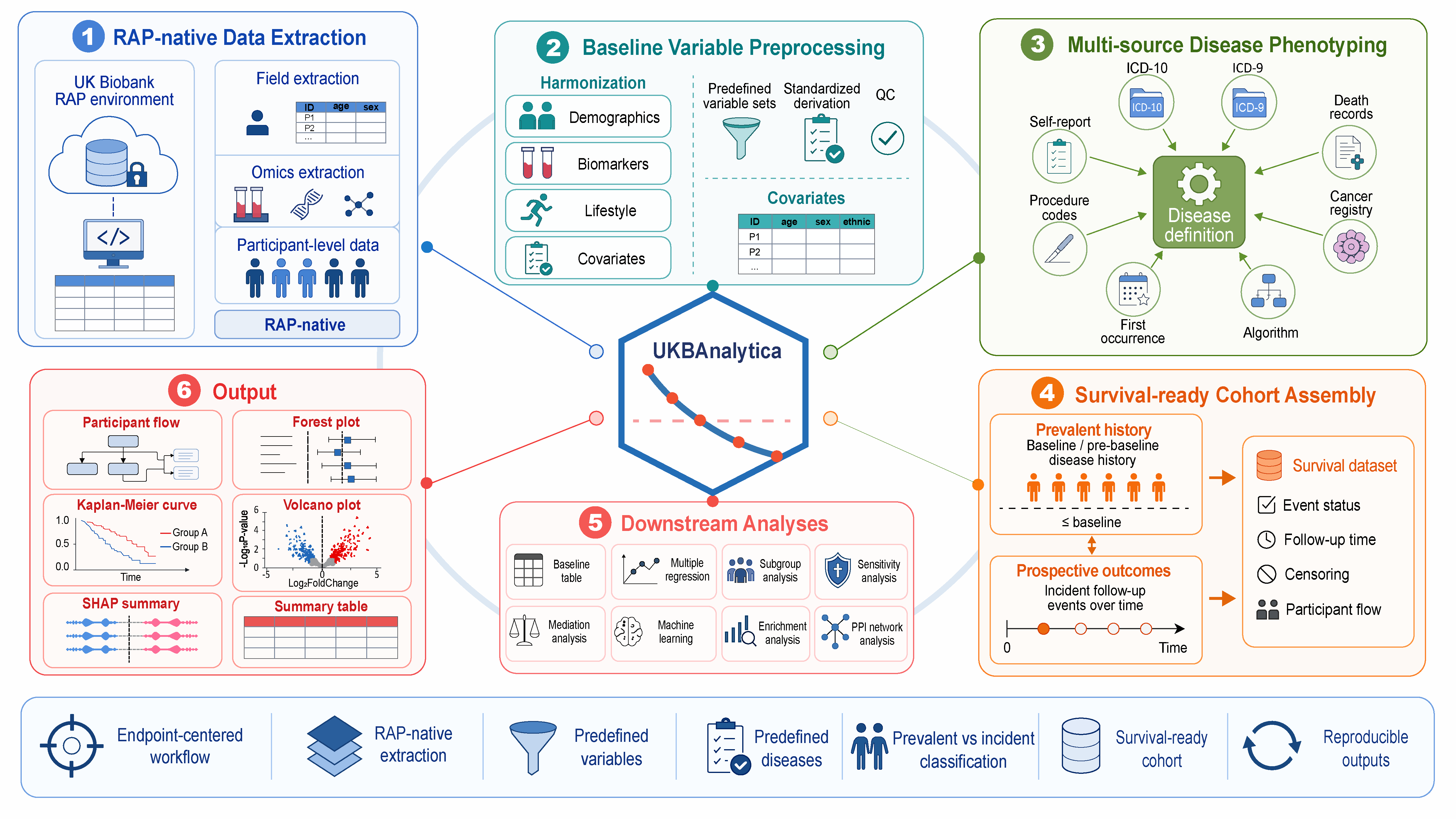
RAP-native extraction
Plan and extract UK Biobank fields within the approved RAP environment.
Baseline preprocessing
Standardize common baseline variables, recode UKB missing-value conventions, and derive reusable covariates.
Multi-source phenotyping
Define disease endpoints using ICD-10, ICD-9, self-report, death registry, OPCS4, cancer registry, first-occurrence, and algorithm-defined outcomes.
Survival-ready cohorts
Separate prevalent history from incident outcomes and compute follow-up time for downstream Cox and survival analyses.
Downstream analysis
Run baseline tables, regression workflows, imputation, subgroup analysis, propensity score methods, mediation, and sensitivity analyses.
ML and omics modules
Support machine-learning workflows, SHAP interpretation, and bioinformatics analyses like proteomics enrichment, and STRING-based PPI analysis.
Workflow overview
Installation
# install.packages("devtools")
devtools::install_github("Hinna0818/UKBAnalytica")
# use pkg like:
library(UKBAnalytica)Minimal example
Run analyses that touch real UK Biobank data inside RAP only.
library(UKBAnalytica)
library(data.table)
## suggest you have a data.frame on your RAP
ukb_data <- fread("population.csv")
## label diseases using the predefined ID in this pkg
diseases <- get_predefined_diseases()[
c("AA", "Hypertension", "Diabetes")
]
## build survival dataset for downstream analyses
analysis_dt <- build_survival_dataset(
dt = ukb_data,
disease_definitions = diseases,
prevalent_sources = c("ICD10", "ICD9", "Self-report", "Death"),
outcome_sources = c("ICD10", "ICD9", "Death"),
primary_disease = "AA",
show_flow = TRUE,
dt_threads = 8
)UKBAnalytica documentation and skills are designed for RAP-based analysis. Participant-level UK Biobank data should remain inside approved RAP project storage. For AI-assisted scripting, users should describe the dataframe schema and intended analysis only; synthetic toy data can be used for interface tests, while real analyses are run by the user inside RAP. Only aggregate outputs or non-identifying rendered figures should be shared for interpretation.
About
Citation
If you use UKBAnalytica in your study, please cite:
N He, K Mo, G Yu, F He. UKBAnalytica: an integrated R package for scalable phenotyping and reproducible epidemiological analysis within the UK Biobank Research Analysis Platform. medRxiv. 2026.06.19.26356057. doi: https://doi.org/10.64898/2026.06.19.26356057